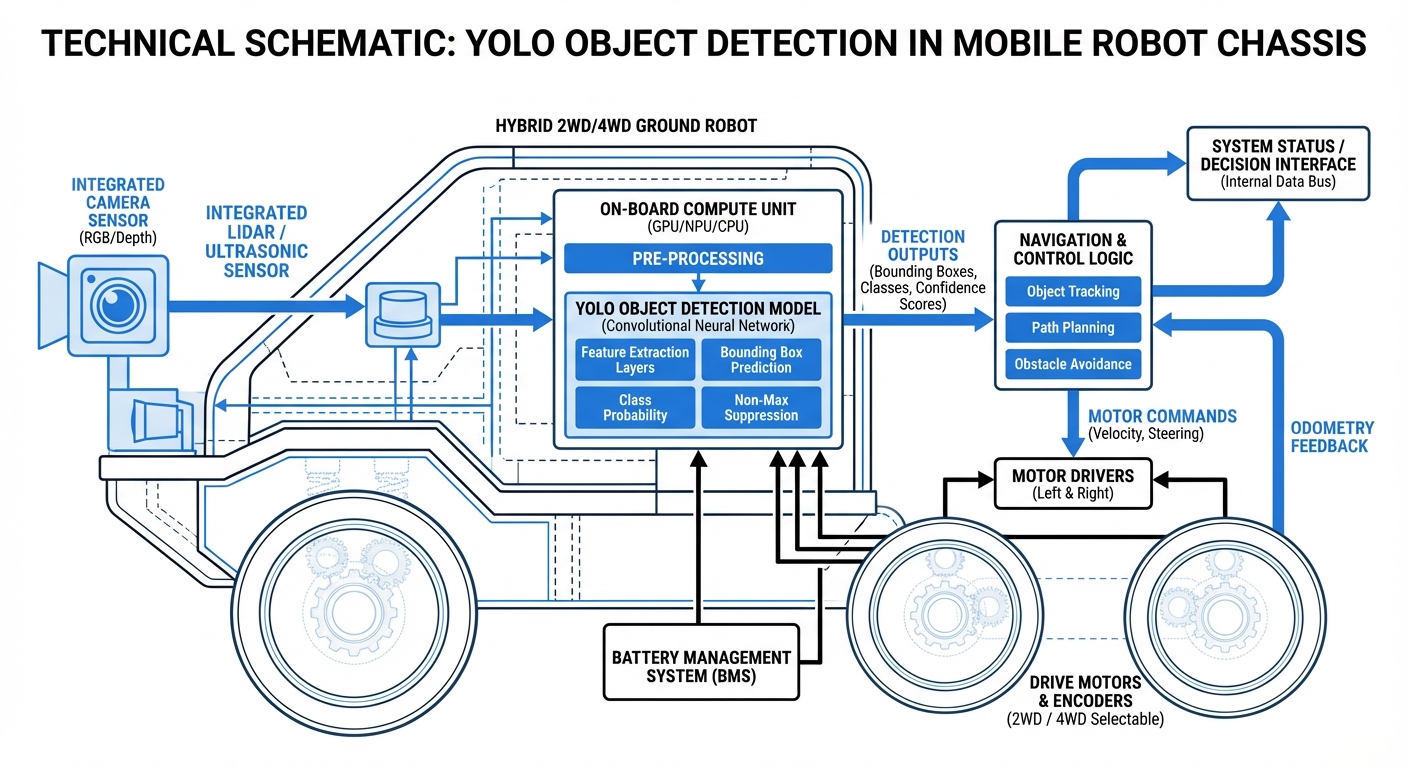
YOLO Object Detection
Supercharge your autonomous mobile robots with the blazing speed of 'You Only Look Once' architecture. Unlock real-time obstacle dodging, smart scene understanding, and pinpoint navigation in bustling warehouses.

Core Concepts
Real-Time Inference
Unlike clunky multi-stage detectors, YOLO scans the full image in one shot. This lets AGVs crunch video at 30+ FPS—crucial for safety at speed.
Grid Division
The image splits into an S×S grid. The grid cell where an object's center lands takes charge of spotting it.
Bounding Boxes
Each cell predicts B bounding boxes plus confidence scores, mapping out obstacles' spots (x, y, width, height) relative to the robot.
Non-Max Suppression
To nix duplicate detections, it grabs the highest-confidence box and squashes overlaps.
IoU Metrics
IoU gauges how accurate it is by measuring overlap between the predicted box and reality—ensuring the robot knows exactly where that pallet is.
Class Probability
It also tags the object's class on the fly (like 'human,' 'forklift,' 'shelf'), so the fleet system can react with tailored logic.
How It Works: The "Single Shot" Advantage
Traditional detectors work in two phases: propose regions, then classify. Accurate, but too slow for speedy robots in crowded facilities.
YOLO (You Only Look Once) rethinks detection as a single regression task. Feed the whole image into a CNN once, and out comes a tensor packed with bounding boxes and class probabilities at the same time.
That's why YOLO rules edge computing on robots with hardware like NVIDIA Jetson—it perfectly balances speed and accuracy for navigation.
Real-World Applications
Human-Robot Collaboration Safety
AGVs tap YOLO to separate static walls from dynamic humans. Spotting a person triggers custom slow/stop rules beyond basic avoidance, meeting ISO 3691-4 standards.
Inventory Auditing
On delivery paths, side-facing cameras with YOLO scan shelves to spot and classify stock—finding empty pallet spots or confirming SKUs autonomously, while updating the WMS live.
Precise Docking & Handling
YOLO models trained on fiducial markers, charge contacts, or pallet pockets provide visual tweaks for the final approach, hitting 99.9% docking success.
Foreign Object Debris (FOD)
In factories, floor debris can trash AGV wheels. YOLO trained on 'debris' classes lets robots detect spills, screws, or waste from afar, reroute safely, and auto-alert maintenance.
Frequently Asked Questions
What is the difference between YOLO and R-CNN for robotics?
R-CNN's a two-stage detector—more accurate but way slower. YOLO's single-stage, speed-focused. For robots reacting in milliseconds, YOLO wins with 30-60 FPS on embedded gear, while R-CNN struggles for real-time.
What hardware do you need to run YOLO on an AGV?
Lightweight versions like YOLO-Nano can handle it on CPUs—think Raspberry Pi—but industrial AGVs usually go for Edge AI accelerators. The NVIDIA Jetson series (Nano, Orin, Xavier) is the industry favorite, delivering the CUDA cores you need for full YOLO models with super low latency and manageable power draw.
How does YOLO handle low-light warehouse conditions?
YOLO thrives on visual input, so it dips in performance when it's dark. We fix that by training on low-light datasets or using tricks like gamma and brightness tweaks during training. In total darkness, pair it with thermal cameras or active IR lights.
Can you train YOLO to spot our custom pallets?
Absolutely—that's one of YOLO's biggest strengths with transfer learning. Grab a pre-trained model and fine-tune it on your own pallet photos. It's way quicker than starting from zero and nails accuracy for your facility's unique stuff.
How does the robot figure out distance to what it detects?
YOLO gives you a 2D bounding box in the image, but no direct depth info. We usually blend that with LiDAR data or a stereo depth camera (RGB-D) for distance. Or, if you know the object's size, just math it out from the box dimensions.
Is YOLO integration compatible with ROS/ROS2?
Yep, there are great packages like `darknet_ros` or `ultralytics_ros` that bundle YOLO inference right into ROS nodes. They spit out topics with class IDs and bounding boxes that your navigation stack can grab instantly for planning paths.
What happens if the robot detects a "False Positive"?
Ghost detections can make robots hit the brakes for no reason. We counter that with confidence thresholds (ditching anything under 50-60%) and checks for consistency over multiple frames. Fusing with LiDAR confirms if there's real stuff there.
Which YOLO version should you pick—v5, v8, or v10?
YOLOv8 hits the sweet spot for most industrial robot jobs today—great speed, accuracy, and easy setup through Ultralytics. Go lighter like v5-Nano if your hardware's super tight and battery life rules all.
How much battery power does running vision AI consume?
Deep learning chews through compute power. A Jetson Orin running YOLO might pull 15W-40W depending on the setting. It's noticeable, but tiny next to your drive motors—and the safety and efficiency wins make it worthwhile.
Can YOLO detect small obstacles like screws or wires?
YOLO used to miss small objects, but newer versions use feature pyramid networks to crush that. It all hinges on camera resolution and how far away things are. For solid small-object detection like FOD, angle the camera down or slow the robot for better detail.
Does the robot need internet access to run YOLO?
Nope—inference happens fully on the edge, right on the robot's computer. Internet's only needed if you want to send images to the cloud later for retraining via active learning to keep improving.
How expensive is it to implement YOLO?
YOLO software is totally open-source. You'll spend on hardware ($300-$1000 for compute and cameras) and time labeling data plus integrating. Way cheaper than 3D LiDAR setups at $2k+, making vision a smart, cost-effective pick.
Ready to implement YOLO Object Detection in your fleet?
Check out our lineup of AI-powered mobile robots built for smart warehouses.
Explore Our Robots