Visual SLAM
Simultaneous Localization and Mapping (SLAM) with visual sensors lets autonomous mobile robots tackle tricky, GPS-free spaces. By crunching camera feeds, AGVs map their world and pinpoint their position in real-time with impressive accuracy.

Core Concepts
Feature Extraction
The algorithm spots standout points—like corners and edges—in each image frame to track motion across frames.
Pose Estimation
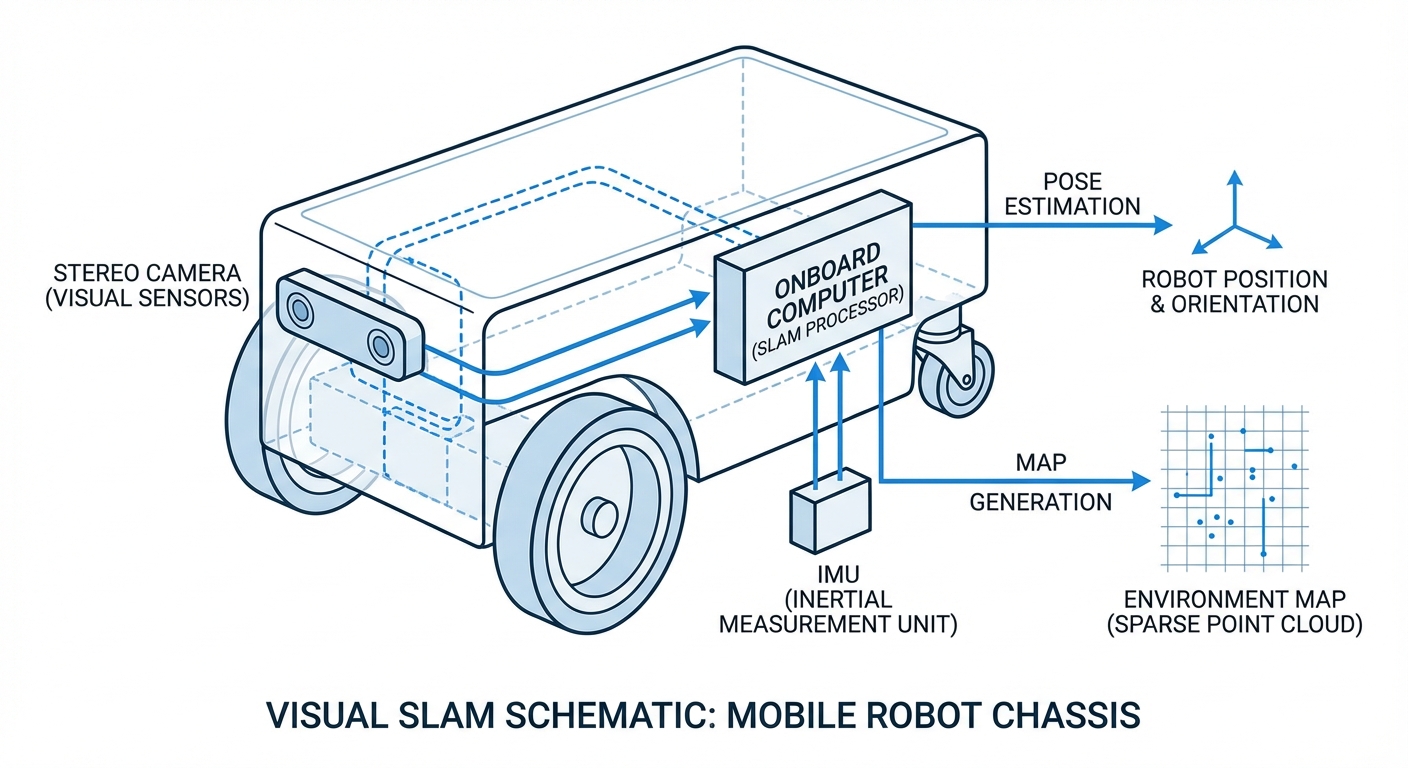
It figures out the robot's 3D position and orientation (6-DOF) from the starting point by watching how those feature points shift.
Loop Closure
The system detects when the robot loops back to a familiar spot, fixing up any drift in the map's path.
Bundle Adjustment
An optimization trick that tweaks 3D scene points and motion parameters to cut down reprojection errors.
Visual Odometry
Figuring out the robot's position and orientation frame-by-frame from the camera images.
Dense Mapping
Unlike sparse mapping that just tracks keypoints, dense mapping builds a full 3D surface model of the surroundings for dodging obstacles.
How Visual SLAM Works
Visual SLAM works like human eyesight. As the AGV rolls along, cameras snap a stream of images. The onboard brain picks out stable anchor points—corners, patterns, textures—that stick around frame to frame.
By triangulating those anchors from different views (thanks to parallax), it gauges object depths and the robot's motion. This builds a sparse point cloud map that grows as the robot explores.
Key bonus: Visual SLAM often teams up with IMU data for 'Visual-Inertial Odometry.' That keeps positioning rock-solid even if the camera hits a blank spot or texture drought.
Real-World Applications
Dynamic Warehousing
In spots where racks and pallets shuffle around a lot, V-SLAM lets AGVs adapt on the fly—no ripping up magnetic tape or QR codes.
Retail & Supermarkets
Inventory bots weave through tight, busy aisles with shoppers. Visual sensors spot obstacles while scanning shelf labels at the same time.
Hospital Logistics
AMRs hauling meds and linens handle long halls and elevators. V-SLAM gives the smarts to tell walls from gurneys and people.
Last-Mile Delivery
Outdoor delivery bots use V-SLAM for sidewalks, leaning on sunlight and building features for spot-on positioning when GPS flakes out.
Frequently Asked Questions
What is the main difference between Visual SLAM and LiDAR SLAM?
LiDAR SLAM fires laser pulses for distances, giving top precision in any light but no color info. Visual SLAM goes with cameras—cheaper overall, packed with semantic goodies like color and texture, but it chews more compute for image crunching.
How does Visual SLAM handle low-light conditions?
Low light challenges standard Visual SLAM since cameras can't pick features. Smart fixes include HDR cameras, robot-mounted LED lights, or blending visuals with IMU to cover visibility gaps.
Does Visual SLAM work on featureless surfaces like white walls?
Pure Visual SLAM stumbles on blank walls without keypoints to track. Fixes? Stereo cameras for disparity-based depth, or infrared structured light to fake some texture.
What is the "Drift" problem and how is it solved?
Drift is those tiny errors piling up, pulling the robot's position off track over time. V-SLAM fixes it with 'Loop Closure'—spotting a known place and realigning the map to reality.
What hardware is required for Visual SLAM?
You'll need a camera rig (monocular, stereo, or RGB-D) and a strong processor (CPU/GPU) for real-time vision work. An IMU is a must for extra toughness.
Is Visual SLAM computationally expensive?
Yes, frame-by-frame video processing is heavy lifting. But edge computing gear and slick algorithms like ORB-SLAM make it efficient on mobile bots without killing the battery.
Can Visual SLAM handle dynamic environments with moving people?
Smart algorithms split static stuff (walls) from movers (people, forklifts). By ignoring dynamic bits in pose estimates, localization stays sharp.
What is the difference between Monocular and Stereo V-SLAM?
Monocular uses one camera and needs motion for depth guesses, with scale staying ambiguous. Stereo pairs two synced cameras for instant, true-scale depth via disparity.
How accurate is Visual SLAM compared to GPS?
Visual SLAM crushes GPS for close-up positioning—often centimeter-level. And it works indoors, underground, or in signal-blocked urban spots where GPS can't.
Can maps created by V-SLAM be saved and reused?
Yes, that's 'Map Serialization.' Map once, save to a server, and the whole fleet downloads it to zip around without remapping.
Does the camera lens require maintenance?
V-SLAM counts on crystal-clear visuals, so keeping lenses free of dust, oil, and scratches is a must. In gritty industrial spots, automated air-puff cleaners or protective housings are go-to solutions for keeping sensors in prime condition.
What is Semantic SLAM?
Semantic SLAM blends mapping with object recognition. Instead of just spotting generic obstacles, the robot actually 'gets' what they are—like 'that's a chair' or 'that's a door.' This unlocks smarter commands, such as 'head to the kitchen,' without needing precise coordinates.