Semantic Segmentation
Turn everyday camera feeds into detailed maps by labeling every pixel. Help your AGVs spot drivable paths, dodge moving obstacles, racks, and people with pinpoint accuracy.

Core Concepts
Pixel-wise Classification
Unlike object detection's bounding boxes, segmentation tags every pixel with a class, nailing exact boundaries.
Drivable Area Detection
A must for AMRs—it separates floor from walls and drops, enabling safe navigation in messy, unstructured spaces.
Convolutional Networks
Powered by U-Net or DeepLab architectures, it crunches visual data, pulls key features, and builds precise segmentation masks.
Contextual Understanding
The model gets object relationships—like pallets on floors or racks—for smarter scene understanding.
Edge Inference
Fine-tuned for NVIDIA Jetson and edge AI hardware to run real-time on battery-powered robots.
Sensor Fusion Ready
Project semantic masks onto LiDAR clouds to add meaning to 3D maps for killer navigation.
How It Works
Semantic segmentation uses an Encoder-Decoder setup. The (often ResNet or MobileNet) shrinks the image step-by-step to grab high-level features—figuring out 'what's' in there.
The grabs those features and upsamples them to full size, piecing back 'where' everything sits.
You end up with a mask coloring every pixel by type (Gray for floor, Red for obstacles). It feeds straight into the AGV's costmap for instant path decisions.
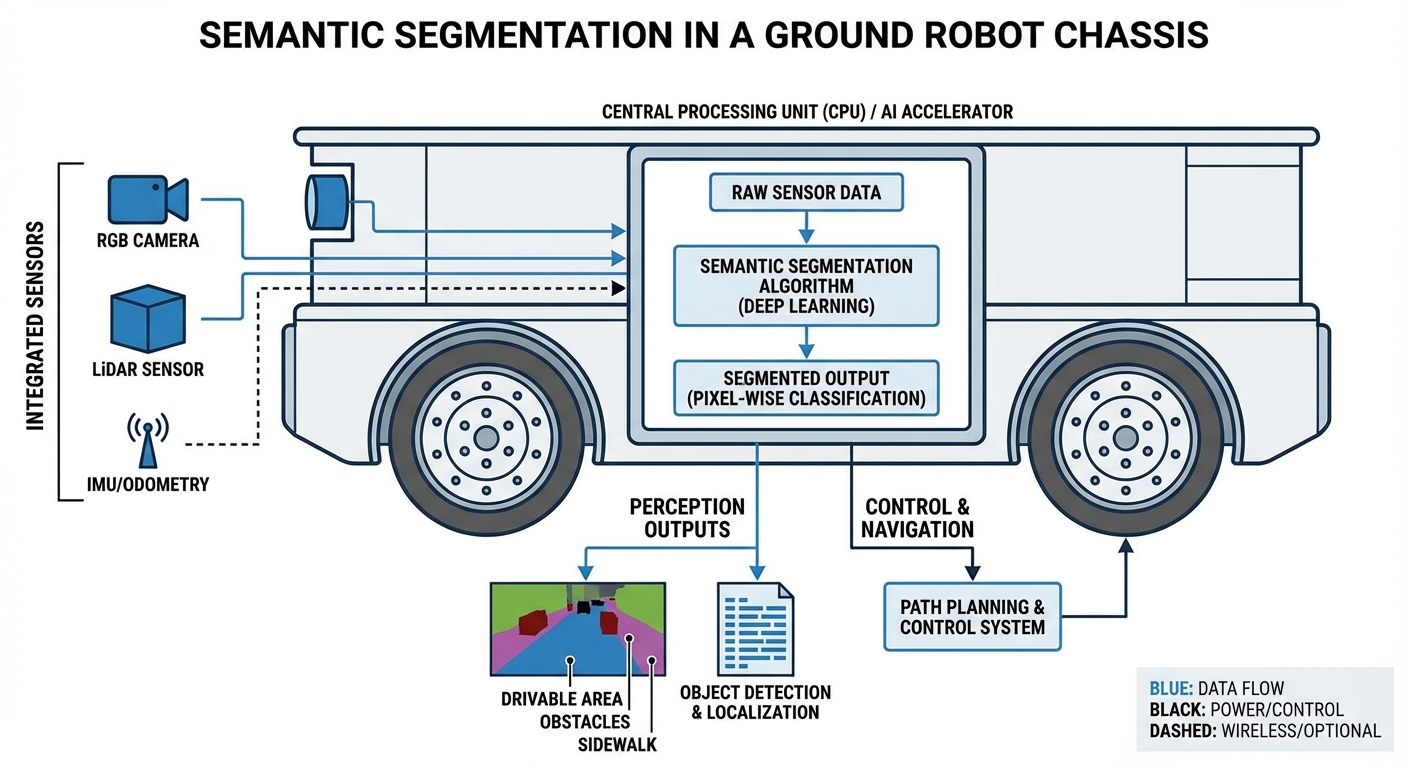
Real-World Applications
Warehouse Free-Space Navigation
In busy warehouses with blocked aisles, segmentation spots the exact drivable floor shape, squeezing through tighter spots than box detection ever could.
Outdoor Last-Mile Delivery
For sidewalk robots, it separates paved paths (go), grass (nope), and roads (danger)—keeping them safely on pedestrian routes.
Advanced Obstacle Avoidance
Telling humans, forklifts, and boxes apart: Slow for people, full stop for forklifts, with custom safety rules per class.
Precision Pallet Pocket Detection
Automated forklifts use it to pinpoint pallet pockets, aligning forks perfectly even if damaged or tilted.
Frequently Asked Questions
What's the difference between Semantic Segmentation and Object Detection?
Detection sketches boxes around objects for rough locations. Segmentation labels every pixel inside for exact shapes. For robot nav, segmentation wins—it shows true obstacle forms and free floor, not boxy guesses with empty space.
Does Semantic Segmentation run in real-time on mobile robots?
Yep, with tweaks. Lightweight backbones like MobileNetV3 plus TensorRT optimization on Jetson hit 30+ FPS. Academic heavyweights are too sluggish for AGVs—we focus on edge-ready speed demons.
How much training data is required?
Segmentation needs pixel-perfect labels, which take work. We start with transfer learning from big sets like COCO or Cityscapes, then fine-tune on your warehouse pics (just 1,000–2,000 images) for spot-on results.
Can it handle transparent or reflective surfaces?
Tough for LiDAR, but vision segmentation nails it with training on glass walls or shiny floors—learning cues like reflections to flag them as no-gos, unlike lasers seeing through.
What happens if the lighting conditions change?
Big light shifts can trip it up. We fight back with HDR cameras and training tricks like random brightness/contrast/noise to make it bulletproof in varying warehouse lights.
What is "Instance Segmentation" and do I need it?
Semantic lumps all 'boxes' together. Instance splits 'Box A' from 'Box B'. Semantic's plenty fast for avoidance; instance is for grabbing specific ones.
How is the segmentation mask used in ROS Navigation?
Camera segmentation projects to the ground plane, mimicking a laser scan or slotting into ROS costmaps—lethal for obstacles, free for floor.
Can this replace LiDAR entirely?
VSLAM is really catching on, but for those industrial safety certifications, LiDAR is still the redundancy champ. That said, segmentation brings the 'understanding' that LiDAR just doesn't have, making your system way smarter and tougher—even if it hasn't totally replaced the depth sensor yet.
What hardware is recommended for running these models?
For embedded robotics, we love the NVIDIA Jetson Orin or Xavier series. These bad boys pack the tensor cores needed to blast through heavy convolutional networks at the frame rates essential for safe robot moves (typically >10Hz).
How do you deal with 'unknown' objects that aren't in the training set?
Most segmentation models shove every pixel into a known class. We use uncertainty estimation—instead, if the model's confidence on a pixel is low (high entropy), we tag it as an 'unknown obstacle' so the robot plays it safe instead of calling it floor by mistake.
Is it possible to update the model after deployment?
Yep, via OTA (Over-The-Air) updates. We grab those edge cases where the robot hesitates, annotate the images, retrain on our server, and beam the improved weights back to the whole fleet—no hardware swaps needed.