Monocular Depth Estimation
Unlock true 3D awareness with everyday single-lens cameras. We use cutting-edge deep learning to turn flat 2D images into detailed depth maps, powering affordable navigation and obstacle dodging for mobile robots.

Core Concepts
Deep Learning Inference
It taps Convolutional Neural Networks (CNNs) or Vision Transformers to predict depth for every pixel from a single RGB image.
Perspective Cues
Smart algorithms spot vanishing points, object sizes, and texture shifts to gauge distances, just like human single-eye vision.
Scale Ambiguity
It solves the "infinite size-distance combos" puzzle by blending IMU data or familiar objects to nail real-world scale.
Self-Supervised Learning
We train on video clips using view synthesis for supervision, skipping costly LiDAR ground truth.
Dense Depth Maps
It spits out a dense point cloud with depth on every pixel—finer than typical sparse LiDAR.
Sim-to-Real Transfer
We pre-train in synthetic worlds (Unity/Unreal) on endless scenarios, then fine-tune on your real robots.
How It Works
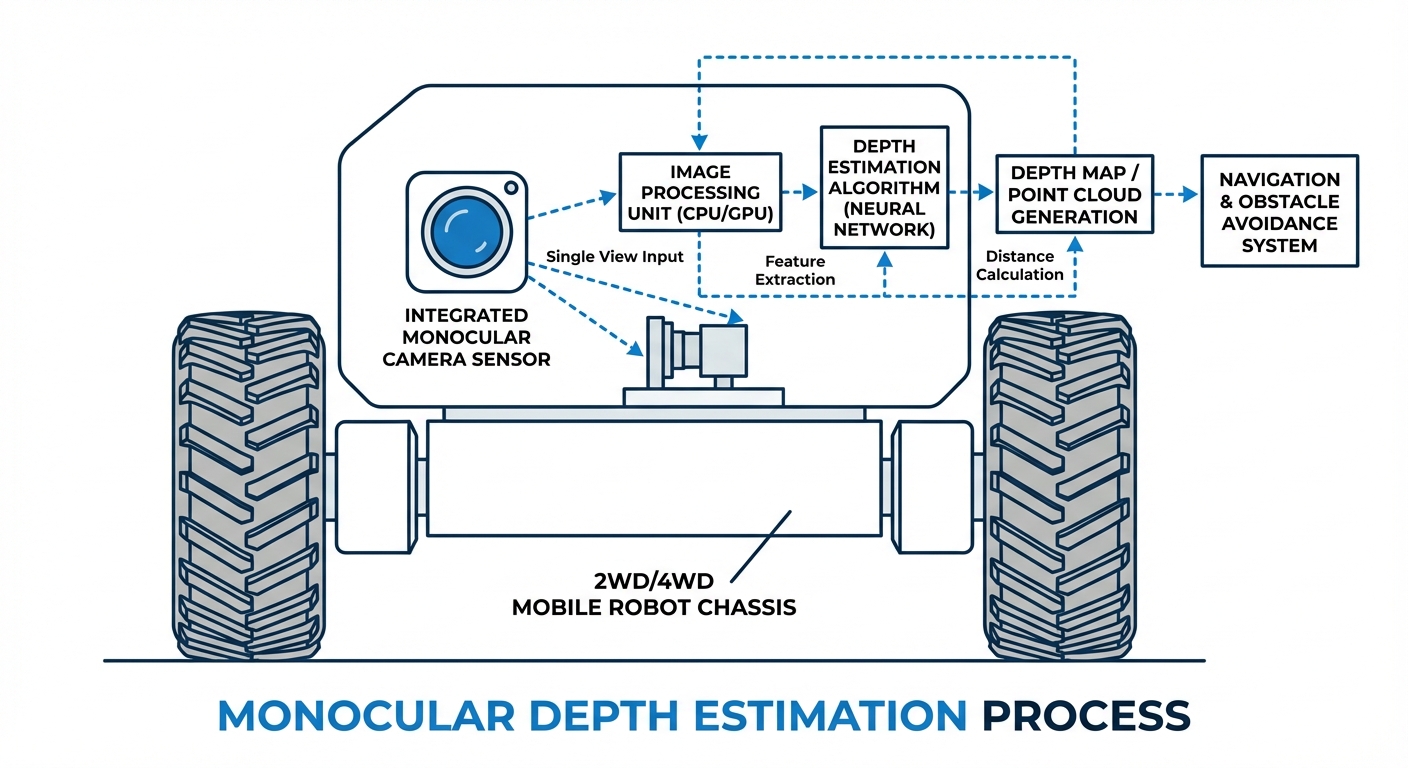
Monocular depth estimation acts like software LiDAR. It kicks off with a regular RGB camera grabbing a frame. That 2D pixel grid feeds an encoder-decoder neural net (usually U-Net style).
The net pulls high-level features like edges, textures, and objects, plus low-level geometry hints. Then it decodes to assign a depth value to every pixel.
Finally, the camera's intrinsics (focal length, optical center) project this 2.5D map into full 3D, generating a point cloud your AGV uses for planning and avoidance—all from one cheap sensor.
Real-World Applications
Cost-Effective Warehousing
Swap pricey 3D LiDAR on AMR fleets. Monocular setups let robots thread tight aisles and catch overhanging hazards that 2D scanners miss.
Last-Mile Delivery Bots
Lightweight sensing for sidewalk robots. A single camera cuts battery drain and weight while spotting curbs and pedestrians.
Drone Navigation
Weight matters big-time for drones. Monocular depth checks landing zones and avoids crashes without bulky sensors.
Domestic Service Robots
Vacuum and mopping bots use monocular vision to tell carpet from cables and furniture, keeping costs low for consumers.
Frequently Asked Questions
What’s the biggest win of Monocular Depth Estimation over Stereo Vision?
The biggest wins here are hardware simplicity, compact size, and lower costs. Monocular systems just need one standard camera—no rigid baseline calibration between two lenses. That shrinks the robot's physical footprint and slashes the Bill of Materials (BOM) cost for mass production.
How accurate is monocular depth compared to LiDAR?
Sure, LiDAR delivers sub-centimeter precision, but today's monocular algorithms nail high relative accuracy that's plenty good for dodging obstacles and everyday navigation. That said, they can falter on absolute scale unless you pair them with an IMU or some ground-truth reference.
Does it work in low-light or unlit environments?
Monocular depth depends solely on what the camera sees, so it tanks in total darkness. Low-light performance has gotten way better thanks to improved sensors and HDR processing, though. For pitch-black scenarios, you'll want active lights like headlights or IR-boosted cameras.
What are the computational requirements for real-time processing?
Running those deep neural networks for depth estimation is a real compute hog. Hitting real-time speeds like 30fps usually means an edge AI accelerator—think NVIDIA Jetson, a dedicated NPU, or a beefy modern CPU. There are lightweight options too, like MobileNet-based encoders, for low-power microcontrollers.
How does the system handle "Scale Ambiguity"?
A single image can't tell scale on its own—a nearby toy car looks just like a distant real one. Robotics setups fix this by blending camera data with wheel odometry or IMU info, or by training on stereo video where the known baseline sets the scale.
Can this technology handle transparent surfaces like glass doors?
Glass trips up LiDAR and stereo vision big time. Fun fact: deep learning monocular methods can sometimes beat them by spotting context like frames and reflections, instead of depending on laser bounces—though it's still a tough edge case that needs targeted training data.
Is it suitable for high-speed AGVs?
Absolutely, as long as inference latency stays low. At 100ms processing time, a speedy robot could blind-travel a good distance. That's why optimizing the model with quantization and pruning for high frame rates is key to staying safe at speed.
Do I need to re-train the model for my specific warehouse?
Pre-trained models from huge datasets like KITTI or NYU Depth work great out of the box, but for peak performance in quirky spots—like super-reflective floors or unique rack colors—fine-tuning with your own site data is a smart move.
How does it handle dynamic objects (people, forklifts)?
Single-frame estimation shines on dynamic stuff because it skips temporal consistency or static assumptions (unlike old-school photogrammetry). It sees a walking person the same as a lamppost, gauging depth from looks and context in that one frame.
What type of cameras are supported?
Pretty much any standard RGB camera does the trick, from global to rolling shutter. Fisheye lenses? No problem, if the model's trained or tweaked for that heavy wide-angle distortion.
Can this replace a safety LiDAR completely?
Right now, for ISO-certified safety zones (where robots stop to avoid hurting people), certified 2D safety LiDARs are the gold standard. Monocular depth shines for navigation, path planning, and obstacle dodging—teaming up nicely with the safety setup.
What software stacks support this?
Most setups run on Python or C++ with PyTorch or TensorFlow. In robotics, they plug right into ROS or ROS2 nodes, spitting out PointCloud2 messages that the nav stack (like Nav2) can use directly.