Human Pose Estimation
Going beyond basic obstacle detection, Human Pose Estimation lets AGVs spot skeletal landmarks and predict what humans intend to do. This smart perception boost makes human-robot teamwork way safer and smoother.

Core Concepts
Keypoint Detection
The system picks out key anatomical landmarks—like nose, shoulders, elbows, knees—from the camera feed to build a skeletal map of the person.
Bottom-Up Inference
It's a bottom-up algorithm approach: detect all body parts in a frame first, then link them to specific people. This keeps things fast even in busy crowds.
Intent Prediction
By tracking the direction and speed of skeletal movements, the AGV figures if a worker's stepping into its path or safely moving away—cutting down on pointless emergency stops.
3D Depth Mapping
Blending RGB data with depth sensors gives the robot a full 3D view of the pose, pinpointing exactly how far limbs are from the chassis.
Edge Processing
Processing skeletal data right on the AGV's GPU (like NVIDIA Jetson) ensures super-low latency, crucial for safety-critical moves.
Occlusion Handling
Advanced models even guess hidden limb positions from visible joints, so the robot can track people partially blocked by shelves.
How It Works
It starts with the AGV's optical sensors grabbing a video stream. That feeds into a CNN trained on human data, spitting out 'Confidence Maps' for body parts and 'Part Affinity Fields' to match them to individuals.
With the skeleton mapped, the navigation stack reads the geometry. No more vague 'blob' obstacles—it sees a person facing left, right, or straight at it.
Finally, this deep understanding feeds the local planner. Spot a human facing it with an arm out (like a stop signal)? The AGV prioritizes halting over just dodging.
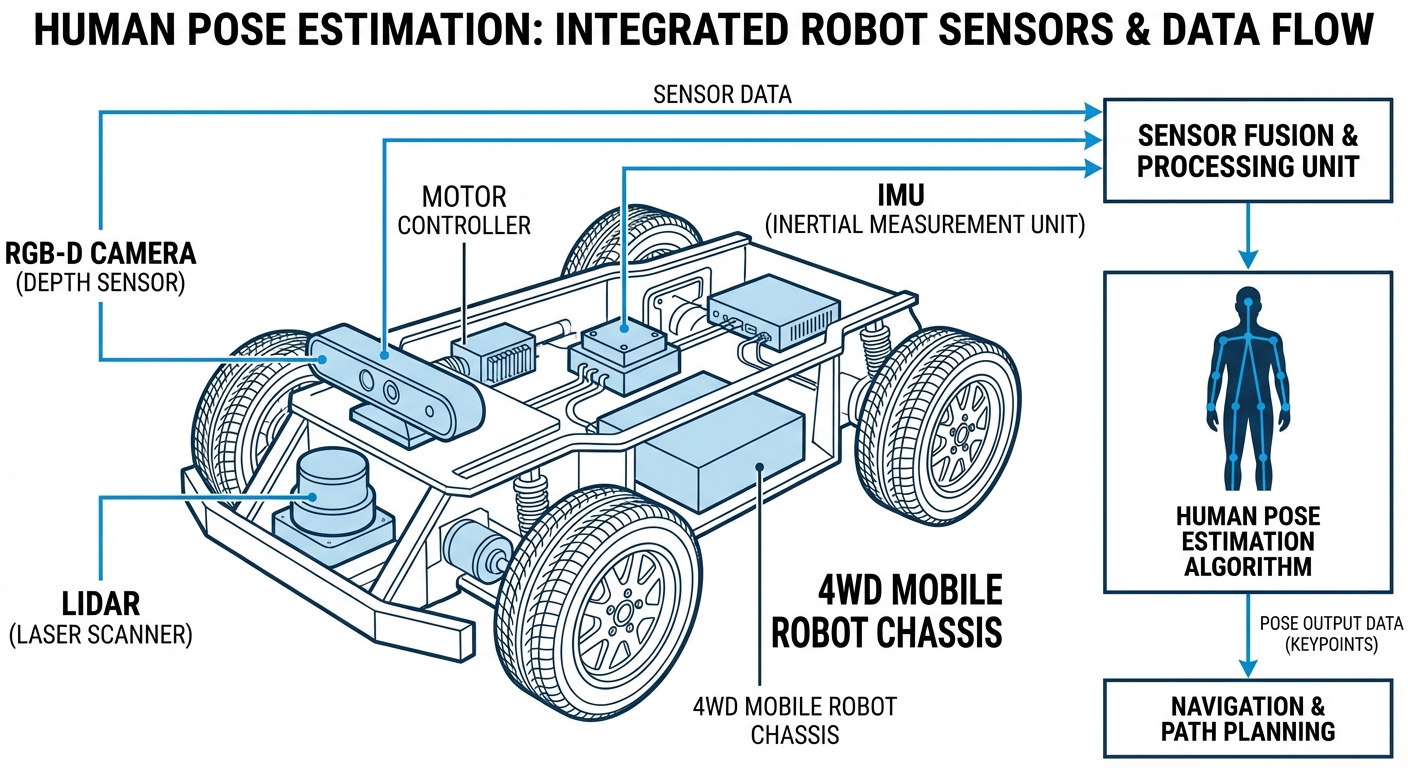
Real-World Applications
Dynamic Warehousing
In warehouses where pickers and AMRs share tight aisles, pose estimation lets robots weave around stationary workers without unnecessary safety halts.
Healthcare Logistics
Hospital delivery bots use pose detection to spot patients on crutches or in wheelchairs, bumping up safety buffers and slowing down ahead of time.
Gesture Control
Operators direct AGVs with simple hand signals—like raised hand for stop or waving to follow—no need for controllers or tablets.
Collaborative Assembly
In manufacturing, robots tweak speed based on a tech's closeness and posture, making safe handoffs smooth on assembly lines.
Frequently Asked Questions
How does Pose Estimation differ from standard LiDAR obstacle detection?
LiDAR spots objects and their distance but lumps humans, boxes, and pillars together as space points. Pose Estimation adds smarts: it IDs humans specifically, reads their posture, facing direction, and likely next moves.
What hardware is required to run Pose Estimation on an AGV?
You'll want a high-res RGB or RGB-D camera plus edge computing with GPU power, like NVIDIA Jetson Orin or Xavier. Basic motor-control microcontrollers can't handle the neural net math.
Does this technology work in low-light warehouse conditions?
Standard RGB pose estimation struggles in the dark. But IR cameras or ToF sensors keep detection going in low light or 24/7 warehouse shifts.
How does the system handle multiple people in the frame?
Modern bottom-up algorithms (OpenPose, MediaPipe) detect all keypoints first, then group into skeletons. This lets the AGV track several workers at once without slowing down much.
What is the typical latency for pose estimation?
On tuned edge hardware, lightweight models (MobileNet-style) hit 30-60 FPS with under 30ms latency—key for weaving into the robot's real-time safety and speed controls.
Is Pose Estimation safety-rated (SIL/PL)?
Right now, most vision-based AI pose estimation acts as a helpful sidekick for smoother efficiency and interaction—it's not the main PL-d safety mechanism. It usually layers on top of certified safety LiDAR zones to make operations flow better, without replacing the core hard-stop safety loop.
Can it detect workers wearing high-vis vests or PPE?
Yes, but you'll need to train or fine-tune the model on datasets with industrial clothing. Standard ones like COCO mostly show casual wear. For reliable factory use, train on specific PPE and high-vis gear to keep keypoint detection spot-on.
What happens if a person is partially hidden behind a rack?
Modern algorithms are great at handling occlusions. If the head and shoulders are visible, the system picks up on the human presence. Navigation treats the area behind as a "potential zone of occupancy" and slows the AGV right down.
Are there privacy concerns with filming workers?
Pose estimation boils humans down to a simple stick figure skeleton of coordinates. No facial recognition or video storage needed. It processes in real-time right on the edge, keeping just the skeletal coords to ease GDPR worries.
How does it integrate with ROS 2?
ROS 2 supports pose estimation widely through packages wrapping tools like MediaPipe or OpenPose. Output lands as a custom message like `PersonList` with joint coordinate arrays, which the navigation stack taps into as a dynamic obstacle layer.
What is the maximum detection range?
It all comes down to camera resolution and lens focal length. On a standard wide-angle nav camera, you get solid skeletal detection from 0.5m to 10m. Past that, folks shrink too small in pixels for precise joint spotting.
Does the robot stop if a person is sitting or crouching?
Yep, strong models train on all kinds of poses—sitting, crouching, even lying down. Crucial for industrial safety, like spotting an injured worker on the floor or a tech hunched over low gear.