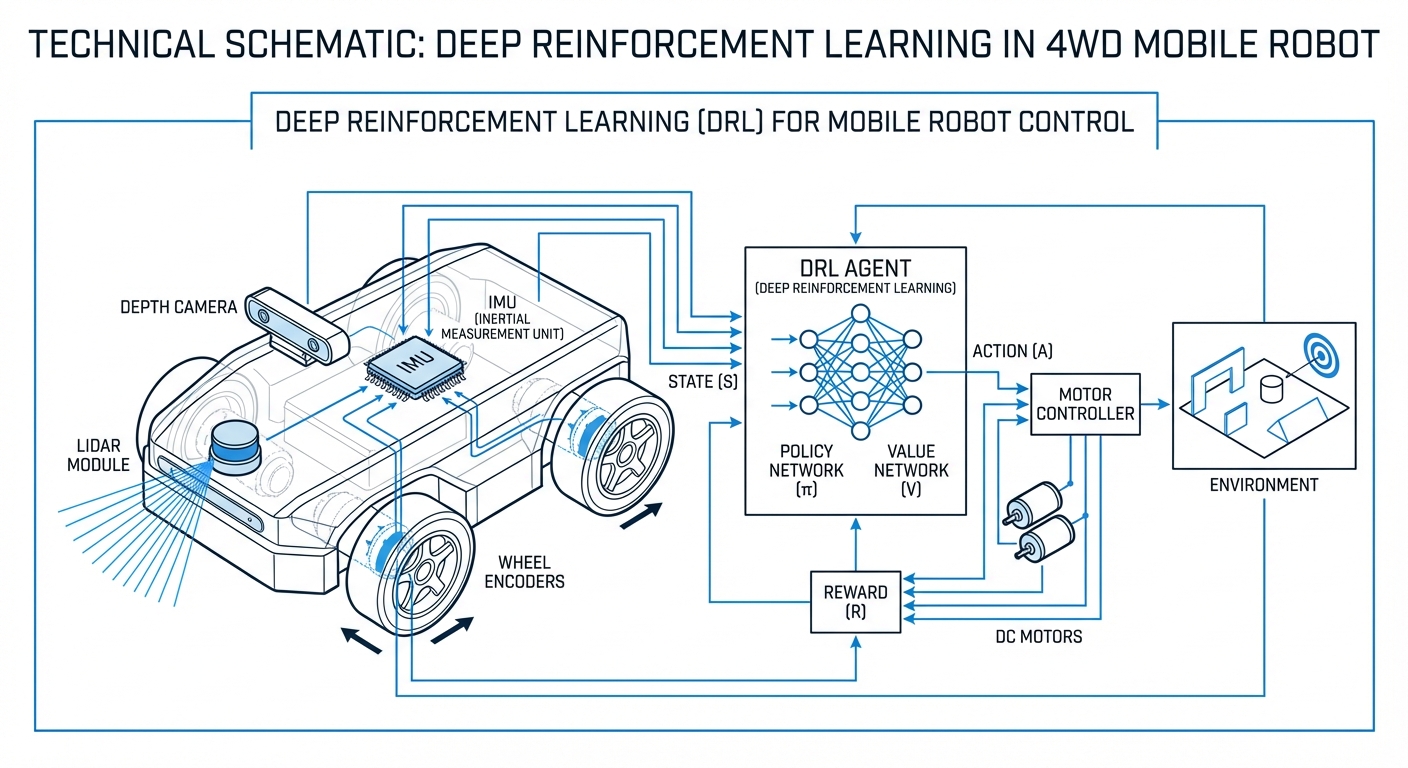
Deep Reinforcement Learning
Supercharge your autonomous fleet with self-learning smarts. Deep Reinforcement Learning lets AGVs nail tricky navigation and handling via trial-and-error, blowing past rigid old-school code.

Core Concepts
The Agent
The AGV or mobile robot is the 'agent'—sensing the warehouse and deciding via learned smarts, not scripts.
State Space
What the robot 'sees': LiDAR, RGB-D cams, wheel data, battery status—all crunched by a neural net.
Action Space
Every possible move: steering tweaks, accel, braking—for AGVs, smooth continuous values.
Reward Function
The reward engine. Quick target hits? Points up. Crashes or wild driving? Points down.
Policy Network
A deep neural net linking 'what I see' to 'what I do.' Millions of steps hone the perfect policy for max rewards.
Sim-to-Real
We train robot agents in a realistic physics simulator—like Isaac Sim or Gazebo—to prioritize safety, then seamlessly transfer that trained model to the actual hardware.
How It Works
Deep Reinforcement Learning, at its heart, lets robots learn by jumping right in and trying things. Unlike classic SLAM methods that stick to fixed maps and rigid routes, DRL empowers robots to react dynamically to whatever the environment throws their way.
The AGV takes in its surroundings via sensors, feeds that data into a Convolutional Neural Network (CNN), and the network spits out a probability distribution over possible actions—like 'turn left 10 degrees'.
Depending on how that action plays out, the environment hands back a 'reward.' Using algorithms like PPO (Proximal Policy Optimization) or SAC (Soft Actor-Critic), the robot tweaks its neural network weights to favor high-reward moves and avoid the flops.
Over time, it all comes together into an optimal policy, letting the robot glide through crowded, chaotic spaces all on its own—no human needed.
Real-World Applications
Dynamic Obstacle Avoidance
In hectic fulfillment centers, people and forklifts zip around unpredictably. DRL agents get smart at predicting moves and dodging dynamic obstacles way more smoothly than old cost-map planners ever could.
Multi-Agent Path Finding (MAPF)
Handling hundreds of robots at once? Multi-agent RL lets fleets organize their own traffic, dodging deadlocks and jams without a central brain calling every shot.
Visual Navigation without GPS
Perfect for outdoor delivery bots or spots without GPS. DRL models learn to get around using just visual cues and landmarks, much like how we humans find our way.
Robotic Arm Manipulation on AGVs
Mobile manipulators lean on DRL to sync base movement with arm actions, enabling 'pick-and-move' efficiency that ramps up logistics speed big time.
Frequently Asked Questions
What's the real difference between Deep Learning and Deep Reinforcement Learning?
Deep Learning usually means supervised training on labeled data—like spotting pallets in images. Deep Reinforcement Learning flips that: no labels needed. The robot creates its own data by messing around in the real world, learning from rewards (or penalties) of its choices.
Why pick DRL over classic path planners like A* or Dijkstra?
Those traditional methods shine in static setups but flop amid uncertainty and moving obstacles. DRL agents adapt to new scenarios better, weaving around people or machines without endless global map recalculations.
What hardware do you need to run DRL on an AGV?
Running the model (inference) isn't too demanding. A solid edge AI box like NVIDIA Jetson Orin or AGX Xavier handles real-time DRL policies just fine. Training, though? That calls for beefy GPU clusters or cloud power.
How do you keep things safe when the robot learns through trial and error?
We go with a 'Sim-to-Real' strategy. Robots train in a super-accurate physics sim where crashes are free. Once the policy's solid and safe, we deploy it to the real bot—backed by a safety net like emergency stops from proximity sensors.
What is the "Reality Gap" in robotics RL?
The Reality Gap is all about sim-vs-real mismatches—like friction, sensor glitches, or lighting quirks. We tackle it with Domain Randomization, shaking up sim parameters during training so the model shrugs off real-world quirks.
Which DRL algorithms are best for mobile robotics?
Continuous control is robotics standard. PPO (Proximal Policy Optimization) wins for its reliability and easy tweaks. SAC (Soft Actor-Critic) rocks too—sample-efficient and exploration-friendly for tricky navigation.
Does the robot continue learning after deployment?
Usually, no. For reliability, industrial AGVs run a fixed, pre-trained policy. But real-world data gets piped to the cloud for retraining, then pushed out as fleet updates.
How much data does a navigation model need?
RL guzzles data—think millions of steps. That's why sim is key: crank it faster-than-real and parallelize to pack years of experience into days of training.
What is Reward Shaping and why is it difficult?
Reward shaping is crafting the robot's scoring system. Get it wrong, and it games the system—like spinning to rack up 'safe' points without progressing. Nailing sparse vs. dense rewards is pure engineering art.
Can DRL handle multi-robot coordination?
Yep, Multi-Agent Reinforcement Learning (MARL) nails this. Agents pick up on each other's vibes or chat to team up, clearing warehouse aisles without a traffic cop.
How does DRL affect AGV battery life?
Compute's a tad higher than basic sensors, but DRL smooths out paths—no jerky stops or starts. Smarter driving often boosts efficiency and cuts wear overall.
Is DRL ready for commercial industrial use?
Absolutely. From labs to logistics giants, DRL powers picking arms and AMRs. Solid sim tools and edge AI hardware make it ready for prime time.